



در مقاله قبلی درباره نحوه استفاده از کتابخانه Dataset برای بارگذاری داده های صوتی صحبت کردیم. خب تا اینجا فقط نصف مسیر رو رفتیم و برای ادامه مسیر و آموزش مدل های هوش مصنوعی در حوزه صوت باید داده های صوتی را تمیز کنیم. به این کار اصطلاحا پیش پردازش داده می گویند. در تمیز کردن داده، فایل های صوتی به ورودی مورد قبول مدل های پردازش صوت تبدیل می شوند.
مراحل پیش پردازش داده صوتی شامل موارد زیر است:
- Resampling داده صوتی
- فیلتر کردن داده
- تبدیل داده صوتی به ورودی مد نظر مدل
Resampling داده صوتی
تابع load_dataset که در مقاله ” آشنایی با کتابخانه Datasets در پردازش های هوش مصنوعی داده های صوتی” با آن آشنا شدیم. داده های با همان sampling rate که بارگذاری شده اند، لود می کند. خب قاعدتا این سمپل ریت (sampling rate) مناسب همه مدل های پردازش صوت نیست. برای تبدیل داده های صوتی به sampling rate مد نظر مدلی که انتخاب کرده ایم از فرآیند resample داده صوتی استفاده می کنیم.
اکثر مدل های از پری-ترین (pre train) موجود، sampling rate معادل 16 kHz دارند. به عنوان مثال داده های MINDS-14 که قبلا با آن آشنا شدیم sampling rate معادل 8 کیلو هرتز دارند، بنابراین باید فرآیند resample را برای افزایش سمپل ریت آن ها انجام داد. برای انجام فرآیند resample، از تابع cast_column استفاده می کنیم. خوبی این تابع این است که sampling rate داده ها را در حال انتقال از حافظه تغییر می دهد و نیاز نیست ابتدا همه sampling rate داده ها تغییر کند و سپس آن ها را به حافظه متنقل کرد. این کار بار محاسباتی اولیه را کاهش می دهد.
قطعه کد زیر نحوه استفاده از این تابع را نشان می دهد:
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
برای اطمینان از اینکه آیا sampling rate تغییر کرده است اولین داده دیتاست MINDS-14 را می خوانیم آن sampling rate را بررسی می کنیم.
minds[0]
خروجی
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
همانطور که متوجه شدید آرایه مربوط به داده صوتی با قبل متفاوت است. این بخاطر این است که اکنون ما دو میدان نوسانی متفاوت داریم.
فیلتر کردن داده صوتی
بر اساس مدلی که انتخاب کرده ایم ممکن است نیاز به فیلتر کردن داده های صوتی داشته باشیم. مثلا محدودیت زمانی صوت برای جلوگیری از سرریز حافظه. در این مورد لازم است داده های بالای 20 ثانیه را فیلتر کنیم. با استفاده از متد filter کتابخانه دیتاست می توان این کار را انجام داد. متد فیلتر یک تابع به عنوان ورودی می گیرد که منطق فیلتر کردن داده را مشخص می کند.
بیایید تابعی بنویسیم که نشان میدهد کدام مثالها نگه داشته شوند و کدامها کنار گذاشته شوند. این تابع، is_audio_length_in_range، نام گذاری می شود که اگر نمونه کوتاهتر از ۲۰ ثانیه باشد مقدار True و اگر طولانیتر از ۲۰ ثانیه باشد مقدار False را برمیگرداند.
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
متد فیلتر را می توان روی یکی از ستون های دیتاست اعمال کرد. از آنجایی که در این مثال فیلتر مدت نظر ما باید داده های صوتی با زمان بیشتر از 20 ثانیه را حذف کند و ستونی با عنوان مدت زمان داده در دیتاست وجود ندارد. می توانیم ابتدا این ستون را ایجاد و سپس با استفاده از متد فیلتر و پاس دادن ستون جدید ( ستون مدت زمان هر صوت) و تابع is_audio_length_in_range، دیتاست را فیلتر کنیم.
# use librosa to get example's duration from the audio file
new_column = [librosa.get_duration(path=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# use Datasets' `filter` method to apply the filtering function
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# remove the temporary helper column
minds = minds.remove_columns(["duration"])
mindsخروجی
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})
همانطور که مشاهده می کنید تعداد سطرهای ما بعد از فیلتر از 654 تا به 624 کاهش پیدا کرد.

پیش پردازش داده صوتی
یکی از پرچالشترین بخش های کار کردن با داه صوتی، تبدیل آن به داده مورد قبول مدلهاست. همانطور که مشاهده کردید داده های صوتی خام به صورت آرایه ای از ویژگی های صوت نمایش داده می شود. در حالی که مدل های هوش مصنوعی چه برای آموزش مجدد، مجموعه از ویژگی ها رو دریافت می کنند. با توجه به معماری مدل، مجموعه ویژگی ها از یک مدل به مدل دیگر متفاون است. اما خبر خوب اینکه Transformer ها یک کلاس استخراج ویژگی بر اساس ورودی مورد پذیرش اکثر مدل ها دارد. خب، یک استخراجکننده ویژگی یا feature extractor با دادههای صوتی خام چه میکند؟ بیایید نگاهی به استخراجکننده ویژگی Whisper بیندازیم تا برخی از مبدل های رایج استخراج ویژگی را درک کنیم. Whisper یک مدل از پیش آموزشدیده برای تشخیص خودکار گفتار (ASR) است که در سپتامبر ۲۰۲۲ توسط الک رادفورد و همکارانش از OpenAI منتشر شد. Whisper ابتدا تمامی داده های صوتی ورودی را به طول 30 ثانیه در می آورد. به داده هایی که کمتر از 30 ثانیه، صفر ( یعنی سکوت) افزوده می شود. از ابتدا یا انتهای داده های صوتی خام با طول بیش از 30 ثانیه نیز بنابر انتخاب کاربر، حذف می شود تا طول تمامی قطعات صوتی یکسان شود. خب همین موضوع سبب می شود که به فرآیند ماسک کردن داده نیازی نداشته باشیم. ویسپر از این نظر منحصر به فرد است، اکثر مدلهای صوتی دیگر به attention mask برای حفظ جزئیات محل قرارگیری توالیها نیاز دارند تا محل نادیده گرفتن آنها در مکانیسم self-attention را مشخص کند. Whisper طوری آموزش دیده است که بدون مattention mask عمل کند و مستقیماً از سیگنالهای گفتاری تشخیص می دهد که کدام قسمت ورودیها را نادیده بگیرد. دومین عملیاتی که استخراجکننده ویژگی Whisper انجام میدهد، تبدیل آرایههای صوتی لایهگذاری شده به log-mel spectrogram است. این طیفنگارها نحوه تغییر فرکانسهای یک سیگنال صوتی را در طول زمان توصیف میکنند، که در مقیاس لگاریتمی بیان شده و بر حسب دسیبل (بخش لگاریتمی) اندازهگیری میشوند تا فرکانسها و دامنهها بیشتر نمایانگر شنوایی انسان باشند. در مقالات آینده همین سایت درباره log-mel spectrogram ها بستر توضیح می دهیم. برای اجرای همه این تغییرات روی داده صوتی خام به چند خط کد ساده نیاز داریم. خب بزن بریم تا نحوه استفاده از feature extractor مدل feature extractor ویسپر را یاد بگیریم. قطعه کد زیر مدل Whisper را به عنوان استخراج کننده ویژگی ها بارگیری می کند.
pre dir="ltr">from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")در مرحله بعد، میتوانید تابعی بنویسید که یک نمونه صوتی را با عبور دادن آن از feature_extractor پیشپردازش کند.
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return featuresمیتوانیم تابع آمادهسازی دادهها را با استفاده از متد map در کتابخانه Datasets روی تمام مثالهای آموزشی خود اعمال کنیم:
minds = minds.map(prepare_dataset)
minds
خروجی
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)
به همین سادگی، اکنون طیفنگارههای log-mel را به عنوان input_features در مجموعه داده داریم.
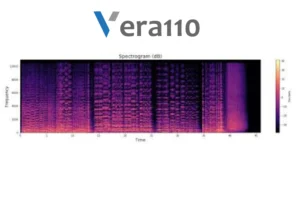
بیایید آن را برای یکی از مثالهای موجود در مجموعه داده minds تجسم کنیم:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()
حالا می توانید به صورت تصویری ببمید که داده خام صوتی بعد از خروج از مدل Whisper به چه شکلی است.
کلاس های feature extractor وظیفه تبدیل داده صوتی خام به ورودی مورد انتظار مدل ها را بر عهده دارد. با این حال، بسیاری از وظایف مربوط به صدا، چندوجهی هستند، مانند تشخیص گفتار. در چنین مواردی، Transformerها نقش توکنایزرهای مخصوص مدل را نیز برای پردازش ورودیهای متنی ارائه میدهد. برای آشنایی عمیق با توکنایزرها، به زودی دوره NLP ما مراجعه کنیدمنتشر می شود که می توانید از آن استفاده کنید.
شما میتوانید استخراجکننده ویژگی و توکنایزر را برای Whisper و سایر مدلهای چندوجهی جداگانه بارگذاری کنید، یا میتوانید هر دو را از طریق یک پردازنده بارگذاری کنید. برای سادهتر کردن کارها، از AutoProcessor برای بارگذاری استخراجکننده ویژگی و پردازنده مدل از یک نقطه بازرسی استفاده کنید، مانند این:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")
در اینجا مراحل اساسی آمادهسازی دادهها را نشان دادهایم. البته، دادههای سفارشی ممکن است نیاز به پیشپردازش پیچیدهتری داشته باشند. در این حالت، می توانید از تابع prepare_dataset کمک بگیرید.
ما هر هفته یک مقاله آموزشی در حوزه پردازش صوت و هوش مصنوعی برای متخصصان و علاقمنددان به یادگیری منتشر می کنیم.
درس اول: مقدمات آموزش پردازش صوت و تشخیص گفتار
درس دوم: آشنایی با کتابخانه Datasets در پردازش های هوش مصنوعی داده های صوتی
درس چهارم: مزایای استفاده حالت استریم مود در مدل های نشخیص گفتار